
AI-enhanced evaluation
Will AI make evaluators redundant? Or could it enable better, quicker, cheaper evaluation, boosting demand and making evaluators busier than ever?

A colleague once commented that it’s risky for an evaluator to work alone. I couldn’t agree more. It takes multiple perspectives and skill sets to rigorously and fairly evaluate policies and programs. Earlier in my career, when I started managing teams, I reflected that everyone brings different strengths, and project teams can be organised to build on each person’s capacities. If someone is brilliant at stakeholder engagement but finds report writing challenging, it makes sense to have them focus on what they do best (unless, of course, they’re keen to develop new skills).
A similar principle applies, I think, when we work with large language models (LLMs), or artificial intelligence (AI) more broadly.1 It’s early days and we’re all figuring things out as we go, but I see an opportunity to combine our respective strengths in ways that enhance our work. Just as we build project teams around complementary skills, we can augment human evaluation teams by tapping into what AI tools do best [see Further Reading at the end: 1,2].
Comparative advantage: specialising based on what we each do best
Comparative advantage is an economic principle based on the idea of one person, company, or country producing a good or service at a lower opportunity cost than another. Even if one party is better at everything (has an absolute advantage), both sides can still benefit by specialising in what they do best, relatively speaking, and trading.
When it comes to balancing human and AI inputs in evaluation, comparative advantage implies we should figure out which functions each is relatively better at and combine our respective strengths to advance good evaluation.2 Even though humans and AI in this context are not trading, the logic of matching agents to activities where their opportunity cost is lowest still applies. For example, if I spend time on tasks that I could delegate to someone or something else, I forgo the chance to use that time on work where my skills have the greatest unique impact. Coordinating our different strengths can produce greater overall benefits.
Increased speed, quality, scope, and reduced cost: can we have it all?
When we team up with AI based on comparative advantage, I think we can expand the project management triangle. Traditionally, it suggests there are trade-offs between time, cost and scope for a given quality. Improving one aspect usually comes at the expense of another - e.g., if you want it quicker, it’ll cost more.
However, could bringing AI into the team break this limitation? If we involve AI for its comparative advantages, while playing to our human strengths, we may be able to do more (scope), better (quality), quicker (time), and cheaper (cost) - expanding the triangle to a new boundary of what’s possible.
When we reach that new (jagged) frontier, the trade-offs will apply again, but at a higher level of productivity, and I expect that future advances will keep pushing out the boundary.
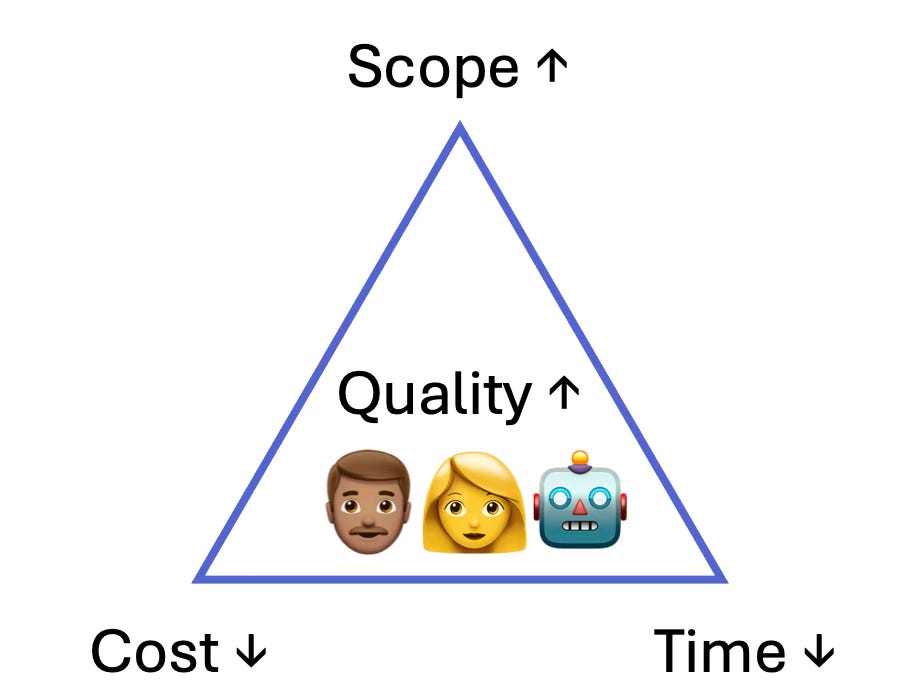
Comparative advantages of human evaluators
Anyone who’s tried out AI models like ChatGPT, Claude, Perplexity or Copilot will have been struck by how rapidly they can generate text, tables, pictures and more - and how those outputs often feel almost, but not quite, right. That’s our clue about the things humans still do best. AI tools are not great at:
Curiosity: It’s one of the things that makes us human. Speaking for myself (and perhaps you too?), I like to explore the unknown, challenge assumptions, make interesting connections and investigate them, and go beyond what’s explicitly requested to see if it adds something useful. I feel motivated not just to answer questions, but also to ask better ones, looking at problems from lots of angles and searching for insight in ambiguity and uncertainty. When I think back, I can recall teachers who wished I was not like that, but it’s stood me in good stead as an evaluator. Though AI models may be programmed or prompted to simulate curiosity, they don’t share our innate drive to discover.
Relationships: Evaluation is about people as much as data. One of the really important things we do as evaluators is build rapport and trust with stakeholders, foster open communication, facilitate participatory processes, adapt our approaches to different stakeholders’ needs, and give honest feedback. People have the social and professional skills to navigate these things with shades of subtlety that AI can guess at but not intuit - because AI models don’t possess things like intuition [1,4,6].
Contextual understanding: Although AI excels at working with context-engineered datasets, it’s not as good as people are with social context. We human beings can tune into the cultural, political, and historical nuances of a program. We tune into subtle cues like body language or tone during human interactions like interviews and focus groups, and we notice the significance of outlier events or rare but important comments [1,4,5]. As individuals, we might each see (and miss) different things, which is one of the reasons we shouldn’t evaluate alone.
Creativity and adaptive thinking: Programs and policies operate in complex, unpredictable environments. Humans retain a distinctive creative edge when it comes to designing innovative frameworks, adjusting evaluation questions and methods on the fly, and distilling sensible findings from messy intel [1,7]. While AI tools can undoubtedly generate novel ideas beyond our initial imagination, the reverse is equally true: due to our fundamentally different cognitive wiring, humans will continue to conceive approaches and interpretations that AI systems might miss. This complementary relationship makes it important for humans to remain in charge of navigating complexity and uncertainty.
Ethics and accountability: Evaluation is a political activity. It examines public policies, programs and interventions, often involving sensitive topics and groups with different interests and vulnerabilities. It’s the responsibility of real people to think ethically, reflect on our own (and AI’s) biases, manage power dynamics and avoid harmful practices. We can be held accountable to codes of conduct and evaluation standards for ethical practice, whereas machines cannot [1,4,6].
Sense-making: AI can help describe what’s happening, but lacks our innate ability to consider the “why” and “so what”. Human evaluators can probe into causal and contributory mechanisms, motivations, and unintended consequences, formulate rich contextual insights, and co-construct meaning with groups of people [1,5,7]. We’re a storytelling species, with the inbuilt ability to translate findings into narratives that resonate with our audiences.
Evaluative reasoning: Scriven’s logic of evaluation describes how claims about the value of anything are structured (whether declared or invisible), based on criteria, standards, and evidence. I’ve found AI to be surprisingly good at suggesting criteria and standards, and using them to reach logical conclusions about value from a set of evidence. But I view evaluative reasoning as more than just a technocratic task. It’s deeply social, political, and ethical. In practice, it can involve mixing systematic structure with deliberative, tacit, and other sense-making strategies. Human evaluators ensure findings are not just technically accurate, but meaningful, actionable, and fair [1,6,8]. Advanced AI can emulate some reasoning strategies - but deliberative approaches, like those discussed by Gates and Schwandt, rooted in collective judgement, inclusive dialogue, and responsiveness to values, remain fundamentally human, relying on stakeholder engagement and ethical context. Just because AI can reason algorithmically does not mean it should make evaluative judgements about human affairs.
{kind=link}
It’s not that AI can’t help at all in these areas; quite to the contrary, we can enlist AI to speed up and automate background tasks that support relationship-building, sense-making, evaluative reasoning, and more. Perhaps AI can even support evaluative thinking, e.g., by checking our work for possible biases and cautioning us against getting too carried away by appealing narratives. But when it comes to comparative advantage - and consideration of what’s ethical and meaningful rather than just what’s possible - these evaluation functions and responsibilities are best regarded as human domains first and foremost [1,7,8,9].
Comparative advantages of AI in evaluation
We’ll only get more-better-quicker-cheaper evaluation with AI if we work with it in the right ways. AI has the comparative advantage in particular aspects of particular tasks - but in my view, it mustn’t carry out any task unsupervised:
World’s quickest and cheapest assistant: It can do a lot to get you started (and sometimes nearly finished) on many tasks. Composing an email. Responding to a tender opportunity (emulating the style of proposals you’ve written before). Proofreading. Designing a survey. And so much more. I have used it to troubleshoot IT problems that would otherwise have been way over my head. Some people use it to perform other tasks they cannot do themselves, like writing code or translating text into different languages. As a writing assistant, AI will generate text faster than you can finish your coffee. Its default writing style is pretty bland and soporific - though you can often customise it to approximate your style, and with a critical eye you can prompt it iteratively to get to a rough draft - at which point I recommend it is best to take over and write the final version yourself. You’re the supervisor responsible for guiding its work and accountable for your use of its outputs.
Brainstorming and scoping: I’m constantly amazed at what AI can fabricate despite having no capacity to really understand, like a program theory, survey, or report structure - and get it nearly right. However, can we agree it mustn’t be used to stand in for real human expertise, judgement, and values?
Rapid research: These days I’m more likely to reach for Perplexity Pro than a search engine, because it’s just so much better at answering my question in a targeted way instead of returning a list of nearly-relevant websites to browse. But I find it works best when I break complex searches into a series of tasks, scrutinise everything for relevance and accuracy, prompt iteratively, and type up the results manually, using my own judgement to decide what is relevant and my own writing voice to tell the story.
Rapid and large-scale analysis: AI tools can manage and integrate diverse data sources. They can identify patterns and anomalies in complex datasets. Machine learning models can forecast future scenarios based on historical data. However, their imperfections - like hit-and-miss theming, overly-glib summarising, and outright hallucination - are well known. Humans should remain responsible for designing the analysis, ensuring data quality, deciding what to explore, and making sense of the outputs [9,3,8].
Automation of routine tasks: Jobs like transcription, data cleaning, and coding of transcripts can be sped up with AI, freeing up humans for supervising and quality-checking the AI’s work. But beware the pitfalls (AI and human) as Martina Donkers wrote here. All automated outputs require careful human oversight to check for errors, biases, unintended consequences, and unmitigated garbage [9,3,7].
Enhancing accuracy and consistency: Algorithms can reduce some forms of human error and bias, applying procedures consistently and reproducibly. Studies in fields like evidence-based medicine have found that even expert human reviewers rarely agree perfectly, and well-tuned AI can sometimes do better on consistency - though it still lacks human-level context sensitivity. Overall accuracy can be improved when both AI and humans are in the loop. I find AI can be very useful in reviewing my drafts for clarity, errors and omissions, but ultimately, we humans remain responsible for accuracy, consistency, and meaning. We are the ones with the skills and responsibility for setting criteria, prioritising themes, interpreting ambiguous cases, checking AI outputs for biases, ensuring that the analysis reflects the values and priorities of stakeholders, and more [8,9,3].
McKinsey reckons “work and workflows will be reimagined as AI-first”. I really hope that won’t apply to evaluation. Ethically, I think humans-first oversight is needed in everything we let AI take on. We mustn’t fall prey to automation bias. Vibe working ain’t good enough. While AI can process and analyse information at scale, it lacks the ability to genuinely “get stuff”, excels at creating plausible-sounding vacuous drivel, and the logic behind its output is opaque (the “black box” problem). It’s easy to be seduced by the confidence with which it writes. For example, when AI provides thematic analysis of interview transcripts, it can give you a report that looks authoritative and comprehensive, but can fail to pick up on important cues that a human researcher would notice.
It’s on us to check everything, which can still be quite time-consuming - and woe betide you if you don’t. A significant risk is that AI systems, trained on existing data, can inadvertently perpetuate or amplify biases present in that data. We absolutely must stay vigilant to this risk, applying an equity lens to spot limitations in AI output and ensure evaluation findings don’t reinforce existing injustices [8,9,1,2,3].
As this video says, you can chat with AI as you would a teammate, not a tool. Ask it questions. Have it ask you questions. Iterate. Give feedback. But don’t take the analogy too far. It isn’t sentient and it doesn’t share our values (beyond the extent to which it is explicitly instructed to pretend).
Sequencing matters when “teaming up” with AI. Before asking AI to analyse transcripts, design a survey, scope a value proposition, outline a report or anything else, human evaluators should kick off the process by organising their own thoughts. This ensures our judgements are rooted in our expertise and reflective thinking, and those of our stakeholders. Subsequently, the AI’s output serves as a touchpoint to consider whether there’s anything extra to consider. This sequence guards against anchoring bias; if we got the AI to go first, we would run a greater risk of accepting its outputs with insufficient critique.3
Augmenting, not replacing effort
I've been an enthusiastic early adopter of both AI and e-bikes, mainly because they appeal to my sense of fun, but also for practical reasons. I think there are some interesting parallels.
Some might see them as “cheating”, but if that’s the case, we were cheating already. We achieved massive gains in cycling efficiency when we added gears. When we adopted spreadsheets, we made huge strides in our efficiency at working with numbers. I see e-bikes and AI not as cheating, but as adding extra layers of capability.
Both e-bikes and AI augment your effort. In both cases, you still have to put effort in. But with their help, you can go further, faster. While e-bikes amplify your muscle power to open up new, steeper, and longer routes, AI amplifies your cognitive work, allowing you to process more data, explore new methods, and generate new insights [7,1].
In both cases, people are still at the helm. The e-bike doesn’t ride itself,4 and AI doesn’t think for you. With an e-bike, you choose your destination, path, level of assistance, and respond to the environment. With AI, you frame the questions, quality-check and interpret the tool’s outputs, and make the final decisions. In both cases, you need to learn how to do it competently and safely. Electric bikes are faster and heavier than “acoustic” bikes, which introduces new risks. Similarly, AI introduces new risks around ethics, quality assurance and the speed with which things can unravel and go horrifically wrong.
Integrating AI into evaluation practice will require new competencies for evaluators, including AI literacy, the ability to collaborate with data scientists, and a deepened commitment to ethical oversight [5,6]. AI can even help us to develop these skills, and to develop evaluation education more broadly [10]. AI also has implications for how we assess the quality of evaluations [6]. As AI’s abilities will continue to evolve and grow, so must our practices. And of course, we need to evaluate the impact of AI (and AI-enhanced evaluation) on people’s lives.
Conclusion
To maximise evaluation’s potential for learning, accountability, and good decision-making, our field needs to turn the value-for-money (VfM) lens on itself. AI’s expanding role is a real opportunity to get more value from our evaluation efforts by freeing us to focus on what we do best (like building trust with stakeholders, making meaning in context, making nuanced value judgements) and powering through the tasks AI is good at [1,8,9,2,3].
If we get the team mix right, we can expand our productivity frontier and do more, better, quicker, cheaper. But the stakes are high: get it wrong, and we'll be contributing to an ever-growing, steaming pile of hokum, fuelling distrust of evaluation.
Will AI make us all redundant? I don’t know any more than you do. But here’s what I think: AI, rather than doing human evaluators out of a job, might enable better, quicker, more affordable evaluations, boosting demand and making evaluators busier than ever. This effect has been seen before in fields as diverse as automobile manufacturing, textile production, law, healthcare, logistics, and digital content creation, where automation and technological advances led to dramatic productivity gains and, as a result, increased overall demand and employment.
However you feel about AI, it’s here, in the evaluations we do and the things we evaluate. Evaluators are already using it, and the choice is to do it well or poorly. We have an opportunity to become experts at blending AI’s analytical power with our human capacities, based on the principle of comparative advantage. We need to use AI ethically, understand the risks and limitations when we do work with it, and discern which tasks should not be delegated to AI. Ultimate responsibility for every evaluation must remain in human hands [1,6,4].
This article was created by average intelligence, with background support from artificial intelligence

Acknowledgements
I’d like to thank Zach Tilton for very helpful peer review. Errors and omissions are mine. Thanks also to Kinnect Group colleagues Judy Oakden, Kate McKegg, Nan Wehipeihana, Adrian Field and Charles Sullivan for sharing stories, reflections and demos on the potential of AI - including the video I mentioned above, the NotebookLM tool that I used to produce this podcast, the “sequencing matters” reflection, and the “average intelligence” quip. All opinions expressed herein are my own, are held lightly, and don’t represent people or organisations I work with.
Further Reading

The following articles are all included in the 2023 Special Issue of New Directions for Evaluation, “Evaluation and Artificial Intelligence”, edited by Sarah Mason and Bianca Montrosse-Moorhead.
Reference numbers correspond to the numbers in square brackets in the text.
Mason, S. (2023). Finding a safe zone in the highlands: Exploring evaluator competencies in the world of AI.
Nielsen, S. B. (2023). Disrupting evaluation? Emerging technologies and their implications for the evaluation industry.
Sabarre, N. R., et al. (2023). Using AI to disrupt business as usual in small evaluation firms.
Reid, A. M. (2023). Vision for an equitable AI world: The role of evaluation and evaluators to incite change.
Thornton, I. (2023). A special delivery by a fork: Where does artificial intelligence come from?
Montrosse-Moorhead, B. (2023). Evaluation criteria for artificial intelligence.
Ferretti, S. (2023). Hacking by the prompt: Innovative ways to utilize ChatGPT for evaluators.
Azzam, T. (2023). Artificial intelligence and validity.
Head, C. B., et al. (2023). Large language model applications for evaluation: Opportunities and ethical implications.
Tilton, Z., et al. (2023). Artificial intelligence and the future of evaluation education: Possibilities and prototypes.
Also see:
Anthralytic’s AI & MERL Resources for Social Impact Professionals.
Gerard Atkinson’s article, Opportunities and Responsibilities for Evaluators in the Age of AI (29 Sep 2025 on the Australian Research Society’s website.
This Video presentation on AI and Evaluation, by Rick Davies (extra points for including the Cubist cover art):
Throughout this post, I use the term “AI” for simplicity. But these systems aren’t “intelligent” in the way we apply this term to humans. The AI tools most of us are using are more accurately referred to as Large Language Models (LLM), and for the most part, that’s what I’m talking about in this post. However, AI also includes computer vision, speech and audio processing, robotics and more. I’m not excluding any of it, but I’m writing mainly with LLMs in mind. LLMs work by analysing loads of text and predicting the most likely next word or phrase based on patterns in their training data. They don’t possess understanding, consciousness, or intent. While some newer AI models incorporate forms of “reasoning”, it’s still fundamentally different from human reasoning. They follow statistical and pattern-based processes, and their reasoning is limited to structured tasks and information present in their training data. They can’t truly comprehend, reflect, or apply judgement as people do. This can be a strength and a weakness, depending how you choose to use the technology.
For context, I regard the defining feature of evaluation as judging the value of something. People place value on things, so if we want to understand value, we have to engage with people. At its core, evaluation is about weighing evidence about programs and policies (e.g., evidence about their quality, success, and what matters to people impacted) and making considered, transparent judgements about how well things are going, what actions to take next, and so on. If you just want a descriptive report on something like monitoring data or a satisfaction survey, AI can bash out an average one for you, but that isn’t evaluation because it lacks explicit human values and value-judgements.
It can still be useful to have an initial “conversation” with AI ahead of a stakeholder workshop to map out possible elements of a theory of change, value proposition, or rubric. The intention is not to drive the discussion but to give facilitators a bit of background support so we can approach the workshop better prepared, with a rough map of the territory, preliminary mental structure for organising feedback, and help us spot any gaps that might be worth raising during deliberations.
E-bikes don’t ride themselves. This one nearly can, but it’s only useful to a human being if the rider knows where they want to go.
I love the discussion of the limitations of AI! These points need a wide audience :)
Great post, Julian. AI in evaluation unpacked.
Thinking about the question if AI will take jobs. Don't think so, things will change and done differently. As you said result will probably be along these lines "...better, quicker, more affordable evaluations, boosting demand and making evaluators busier than ever." I would just say that "better" part will depend on human touch and knowledge to use the tool with all its limitations and flaws.
Another aspects worth exploring further are "quicker" and "busier". Do you think that once AI supported evaluations are acknowledged as a mainstream way of doing things, average number of days per evaluation will going down? For example what was expected to be done in 50 paid days now will be 20 or 30 days in average? Maybe even with reduced day fee? Will busier part be a need for more contracts to earn the same amount? And re "boosting demand" will greater demand be sufficient to fill the gap? Of course, nobody know the future but anyway intetested in your view. Cheers