

Sense-making with stakeholders and rubrics
Sense-making with stakeholders and rubrics
Principles and processes

Rubrics are versatile tools to support evaluative reasoning - the process of judging the value of something. Rubrics articulate criteria (aspects of value) and standards (levels of value) that act as a scaffold to guide us in making sense of evidence and rendering a judgement. Though there are other approaches to evaluative reasoning, I often use rubrics.
Superficially, a rubric is a matrix of criteria and standards. Beneath the surface, a rubric supports clarity by making evaluative reasoning explicit. But at their heart, rubrics support relational evaluation and power sharing in determining what good looks like. Rubrics can also assist in collaborating with stakeholders to make sense of evidence and make judgements about quality and value.

Rubrics don’t make judgements - people do. This is a post about which people, and how.
Sense-making is a step in a process
I help people use an approach to evaluative reasoning that follows a sequence of 8 steps. This process is designed to be practical for experienced evaluation teams to use, intuitive for new evaluators to learn, and inclusive for people who are new to evaluation.
One of the features of this process is that it separates evaluation methods (how we plan, gather and analyse evidence - steps 4, 5, and 6) from evaluative reasoning (how we make judgements). The reasoning happens in advance of the methods, at steps 2-3 when we develop an agreed set of criteria and standards aligned with the program and context. It also happens after the methods, at step 7 when we use the criteria and standards to make evaluative judgements about quality and value.
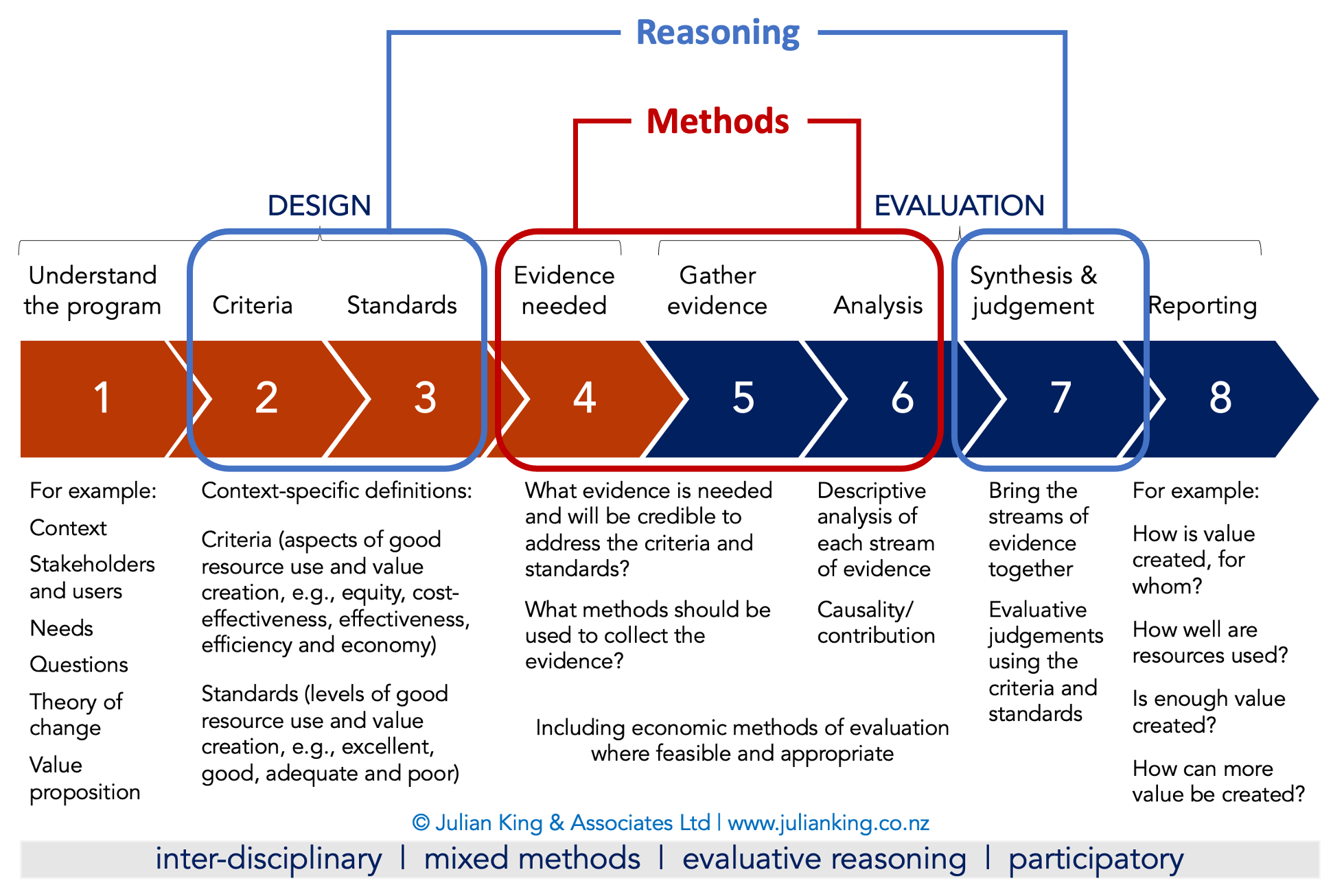
This post is about step 7
This post is a follow-on from an earlier one on developing rubrics with stakeholders (steps 2 & 3). This time I’m here to talk about step 7: using rubrics with stakeholders to synthesise and make judgements from evidence. Thank you to the reader who requested this post several months ago, and thanks for your patience!
Synthesis and judgements
The purpose of Step 7 is to interpret evidence through the shared lenses of agreed rubrics. The prism is a metaphor for the process of systematically combining multiple pieces of evidence, tacit knowledge and values to help make sense of complexity and reach a place of transparency, honesty and clarity in order to make valid judgements.

Synthesis is a distinct and separate step from analysis. While analysis (step 6) involves examining pieces of evidence separately, synthesis (step 7) involves combining all the elements to make sense of the totality of the evidence collected.
The expert knowledge of stakeholders contributes to sense-making, and one of our jobs as evaluators is to bring the right mix of people together and empower them as experts in their own right, to help interpret the evidence.
“A collaborative, social practice” (Schwandt, 2018)
Thomas A. Schwandt has described evaluative thinking as a collaborative, social practice - and I agree. This includes collective, interactive processes of deliberation when co-designing evaluation frameworks and during evaluative sense-making. The diagram below summarises the sorts of questions we can and should address collaboratively when developing and using rubrics.
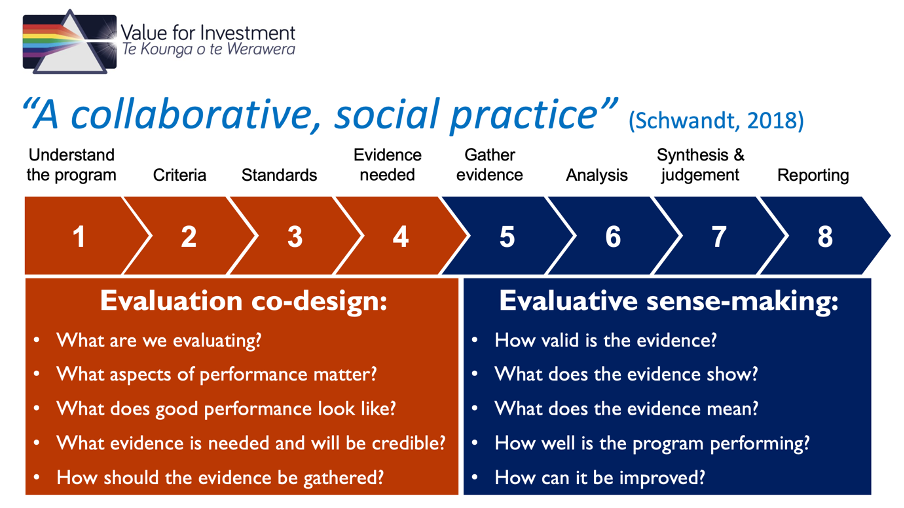
Why collaborate with stakeholders?
There are some important principles sitting behind this process, which reflect my orientation as an evaluator - supported by literature and informed through my experience and my colleagues’ experience about what helps to make an evaluation valid, credible, fair, and cost-effective.
Evaluation is a judgement-oriented practice - it goes beyond descriptive analysis of evidence to make value judgements.
Those value judgements need to be warranted - supported by evidence and logical argument.
Those warrants are assisted by criteria and standards, articulating what aspects of performance matter and what level of performance constitutes ‘good enough’ or better.
Those criteria and standards are determined on the basis of values - an expression of what matters to people.
Those values shouldn’t come from just people commissioning the evaluation and people who evaluate for a living - we need to understand the values of people whose lives are affected by the policy or program.
People whose lives are affected have a right to a voice in the evaluation. Stakeholder empowerment, engagement, and collaboration aren’t merely a methodological option - they’re imperative. Stakeholders should have a role in determining what matters (criteria), what good looks like (standards), what counts as credible evidence, and in making sense of the evidence.
That’s the why. How and to what extent to involve stakeholders is a contextual decision. There are always going to be budgetary, time and capacity constraints. Doing too little would be unethical and a risk to the quality of the evaluation. Too much would be unethical use of time and resources that could be better used in alternative ways. Somewhere in between is a workable balance, proportionate with the value and importance of the evaluation.
Deciding who to involve
In an earlier post on developing rubrics with stakeholders, I talked about bringing the right people together. Determining who should be there for sense-making is a contextual decision, based on the same considerations that applied at steps 2-3. As Jane Davidson wrote, these considerations include:
Validity – Whose expertise is needed to get the evaluative reasoning right? As well as a lead evaluator with expertise in evaluation-specific methodology, it will be necessary to include people with expertise in the subject matter; in the local context and culture; and in interpreting the particular kinds of evidence to be used.
Credibility – Who must be involved in the evaluative reasoning to ensure that the findings are believable in the eyes of others?
Utility – Who is most likely to use the evaluation findings (i.e., the products of the evaluative synthesis)? It may be helpful to have primary intended users involved so that they can be part of the analysis and see the results with their own eyes. This increases both understanding of the findings and commitment to using them.
Voice – Who has the right to be at the table when the evaluative reasoning is done? This is particularly important when working with groups of people who have historically been excluded from the evaluation table such as indigenous peoples. Should programme/policy recipients or community representatives be included? What about funders? And programme managers?
Cost – Taking into consideration the opportunity costs of taking staff away from their work to be involved in the evaluation, at which stages of the evaluative reasoning process is it best to involve different stakeholders for the greatest mutual benefit? (Davidson, 2014, p. 8)
To a large extent, this may be the very same people who were at the table with you during evaluation design. However, it may also differ if there has been some turnover in key roles or if additional people emerged during the evaluation process whose perspectives are important to contribute to sense-making.
The basic process
The synthesis step involves comparing the totality of evidence with the definitions of quality and value set out in the rubrics, using the rubrics to guide the process:
Pick a rubric
Look at all the evidence that’s relevant to the rubric
Look at the definitions in the rubric
Look back at the evidence
Look back at the rubric
Discuss it as a group
Argue a bit
Arrive at a conclusion
Then do it all again for the next rubric, till you’re done.
Here’s an example of how you could structure this process
Usually, the way I structure the evaluation framework, the sense-making process and reporting findings is to have a set of Key Evaluation Questions (KEQs), a few criteria (where relevant) for each KEQ, and a rubric for each criterion. This is of course just one option. I find it’s a practical approach that helps to break the work into manageable bite-sized pieces. I wrote about it here.
For example, say an evaluation has three KEQs:
How does the program create value, and for whom?
To what extent does the program create worthwhile value from the resources invested in it?
How can the program create more value?
KEQ 1 is a descriptive question. We don’t need rubrics for this one. We may opt to treat it as a theory-building exercise, using the evaluation to develop and refine a theory of change and value proposition for the program. Or we might thematically report what came through from stakeholder interviews and other evidence.
KEQ 2 is a summative question and it’s explicitly evaluative (a ‘how good’ question). We can address it by developing rubrics that define what ‘worthwhile value for investment’ looks like. If, for example, we choose to use the 5Es, we would have five overarching criteria (economy, efficiency, effectiveness, cost-effectiveness, and equity). We can develop a separate context-specific rubric for each criterion, like this example:

Each of these rubrics is a table of sub-criteria and standards. To illustrate, in the example above, sub-criteria of economy include maximising value in procurement and keeping unit costs of key inputs within agreed parameters. In order to answer KEQ 2, we’ll rate performance for each of the five criteria individually, and then across all criteria collectively to provide a summative answer to the evaluation question.
KEQ 3 is a formative evaluation question - focusing on opportunities to improve - and the same rubrics can make a contribution toward answering this question too. We can look systematically across the five criteria and their sub-criteria to identify strengths and areas for improvement.
So, our strategy to address KEQs 2 and 3 is systematic, addressing the rubrics one by one, comparing the relevant evidence with the criteria and standards in order to determine to what level of performance the evidence points.
Expect some ambiguity
Usually, the evidence won’t all point unanimously to one level of performance. There may be some debate about where the centre of gravity sits overall.
For example, your program might meet all of the sub-criteria for ‘adequate’ performance on (say) efficiency, and nearly all of the criteria for ‘good’ efficiency with one key opportunity to improve. Does that mean its performance on efficiency should be judged adequate or good overall? You could apply a hard and fast decision rule that says you can only give a rating of ‘good’ if all of the sub-criteria are met at that level. But you might want to allow for a bit more nuance to deliberate on what is a fair judgement. It might depend on the nature of the shortcoming - is the program lacking a critical feature of good performance, or falling short on a minor technicality that shouldn’t carry much weight in the overall judgement?
It can help in these deliberations to use a set of pattern spotting questions, which I think originated from Bob Williams and have been adapted by others including the Human Systems Dynamics Institute and Judy Oakden, from whom I first learnt of them:
In general, to what level of performance does the evidence point?
Are there any outliers or exceptions that might modify your judgement?
Are there any contradictions to weigh up? (on the one hand, on the other hand)?
Does anything surprise you? (if so, check your own assumptions/bias)
Any puzzles? Why might we be seeing this pattern? Do we have sufficient evidence to make a sound judgement? Any evidence missing?
If you feel stuck between two levels, I recommend having a set of generic definitions to refer to, taking us back to the big picture. For example:

If you still feel stuck between two levels, I would tend to err on the side of choosing the lower of the two. However, it is always a contextual decision.
The process is flexible and you’ll need to adapt it to circumstances
There are hundreds of ways you could approach this sort of participatory process. The key is good facilitation to surface different viewpoints and ensure everybody’s voice is heard while managing time and getting through all the rubrics and evidence. We all bring our own personalities and facilitation approaches to the work. It’s for you and your stakeholders to agree on a process that fits the context. Here are a few considerations.
Set clear expectations about the role of stakeholders in sense-making
Be clear about the perspective the evaluation will take when the final report presents evaluative judgements. For example, if it’s an independent evaluation then the evaluation team will be responsible for the final judgements, after hearing and weighing stakeholders’ perspectives. The evaluators will balance the need to acknowledge different viewpoints with the requirement to remain impartial and provide an external perspective.
On the other hand, some evaluations are designed to be stakeholder-led, with the final judgements being reached through deliberation. In this case, the job of the evaluators is to facilitate the process, help stakeholders reach clarity, and faithfully report their collective judgements.
Stakeholders are busy people
There’s a balancing act between how much synthesis and sense-making happens before, during and after stakeholder engagement:
Before stakeholder engagement, the evaluation team will often go through an internal process of deliberation and make preliminary judgements.
During stakeholder engagement, the evaluators will invite people to consider what the evidence means and how the program’s performance measures up against the rubrics.
After stakeholder engagement, back at the evalcave, the team will reflect on the feedback received and what judgements are warranted.
In theory, all sense-making could be done with stakeholders. Under this scenario, the evaluators would prepare draft analysis of evidence, provide the analysis to stakeholders in advance, and facilitate discussion to do all the synthesis, sense-making and judgement-making together. I’ve been involved in a few projects where we were able to come close to this.
However, I’ve usually found people are too busy to commit large and possibly multiple chunks of time to participate in this process. We have to balance time constraints with comprehensiveness to get meaningful and cost-effective stakeholder involvement in sense-making. Pragmatically, in my experience we’ve tended to have a first crack at sense-making and judgement-making as a team, leaving all judgements open to debate with stakeholders.
I think this approach is defensible when we’re using rubrics that we co-created with stakeholders. Having an agreed set of rubrics means we’re carrying their values with us throughout the evaluation, so it’s OK to have a tentative go at some judgements as long as we seek stakeholder input before finalising.
We often prepare a PowerPoint summary of top-line findings and preliminary judgements, and present these to stakeholders as conversation-starters. Through this process stakeholders may validate, contextualise, and/or challenge our preliminary findings. It’s a good opportunity to discuss potential next steps for the program too. In this way, the sense-making workshop is one of the most valuable contributions an evaluation can make. We’ve often noted that by the time the final report is written, recommendations are redundant because actions have already been taken!
Combine synthesis strategies
In a previous post I unpacked rubrics and other ways to manage synthesis and evaluative reasoning. I noted that we can mix synthesis strategies. For example:
Rubrics and deliberative approaches: The process I’ve described above involves using rubrics as a framework to guide deliberation with stakeholders. Co-constructing rubrics, and using them to make sense of evidence, brings structure and focus to the deliberations.
Rubrics and tacit approaches: We also invite people to tacitly consider whether evaluative judgements “feel right” as a strategy for exposing issues that may need further consideration.
Rubrics and cost-benefit analysis: CBA synthesises monetary valuations of costs and benefits to determine the net present value (NPV) of a program. But the NPV is just an indicator. We still have to make a judgement and that judgement might take more into account than just the NPV. Sounds like another job for rubrics! And stakeholders.
One workshop, or more?
With a small stakeholder group and a small evaluation, it may be possible to complete a sense-making process in a single two-hour (or so) workshop. On the other hand, it may be necessary to run multiple workshops, which could involve different sub-groups of stakeholders and/or different sub-sections of the evaluation. Sometimes it can help to approach this engagement as a series of concentric circles, like ripples in a pond - e.g., first an intensive session with small group of key stakeholders, then a lighter-touch consultative session with a wider group, and finally a report-back to a larger audience (still allowing the opportunity for feedback and questions).
Zoom, or room?
These engagement processes ideally benefit from face-to-face engagement. The work we do is relational and happens most effectively when we know and trust each other as people (i.e., as more than just the professional hats we each wear) and feel safe to risk asking ‘silly’ questions (no such thing) and challenging each other’s viewpoints.
However, meeting in person isn’t always possible, and over the last few years we’ve all learnt to run effective meetings through videoconferencing platforms. In one project we also set up a temporary ‘chat room’ in the form of a Google Doc for two weeks, where stakeholders could add comments to our preliminary analysis, synthesis and judgements before and after a Zoom workshop.
Far from being ‘extra work’, sense-making with stakeholders makes writing easier
It turns out that investing in these processes before writing the evaluation report helps to make the writing more efficient and effective: The report essentially covers the same themes we’ve already discussed in workshops. Preparing and presenting the PowerPoint summary gets us close to having a reporting structure and key themes already sorted, and the conversations help the evaluation team to find nuanced ways of expressing complex findings. Reports prepared after sense-making with stakeholders tend to receive high levels of endorsement with very few revisions.
Ideally, therefore, I recommend completing sense-making before writing the report. But there are always exceptions, and in some cases it’s necessary and can be effective to use a preliminary draft report to prompt engagement and draw out discussion. In a recent project, a draft report circulated the globe by email, accumulating feedback as it went. A videoconference was offered but deemed unnecessary.
Just do it!
A collaborative sense-making process contributes to evaluation validity and credibility by incorporating multiple perspectives. It promotes stakeholders’ understanding, ownership and use of the evaluation. It reduces the risk of criticism of evaluation methods or findings at the end of the evaluation. And it’s simply an ethical thing to do. I find it’s one of the most satisfying and rewarding aspects of the job, makes us more effective in our work, and pays back in clarity when the time comes to write the report.

Other posts on rubrics and evaluative reasoning: